One cardinal misunderstanding burning teams, tanking projects and killing products since the dawn of software is the assumption that software development can be reduced to the aspect of producing code.
Software development is talking: Speaking and listening to peers, colleagues and stakeholders. Software development is thinking: Thinking alone by modeling data, testing abstractions, thinking through cases, thinking together by reading other people’s thoughts. Software development is typing: Writing code, but also: Comments, readmes, specifications, code reviews, tickets, mails, …
Overemphasizing one of these aspects or neglecting others is a sure fire way for personal all professional frustration.
Inspiring piece. The better and more advanced you get at testing your code for all eventualities and scenarios, the easier it is to loose out of sight that you will never produce perfect software, there are just too many modes of failure. Hence “Testing in Prod” is not an artifact from times long gone, it is a reality and your org needs to be able to do it.
A system’s resilience is not defined by its lack of errors; it’s defined by its ability to survive many, many, many errors.
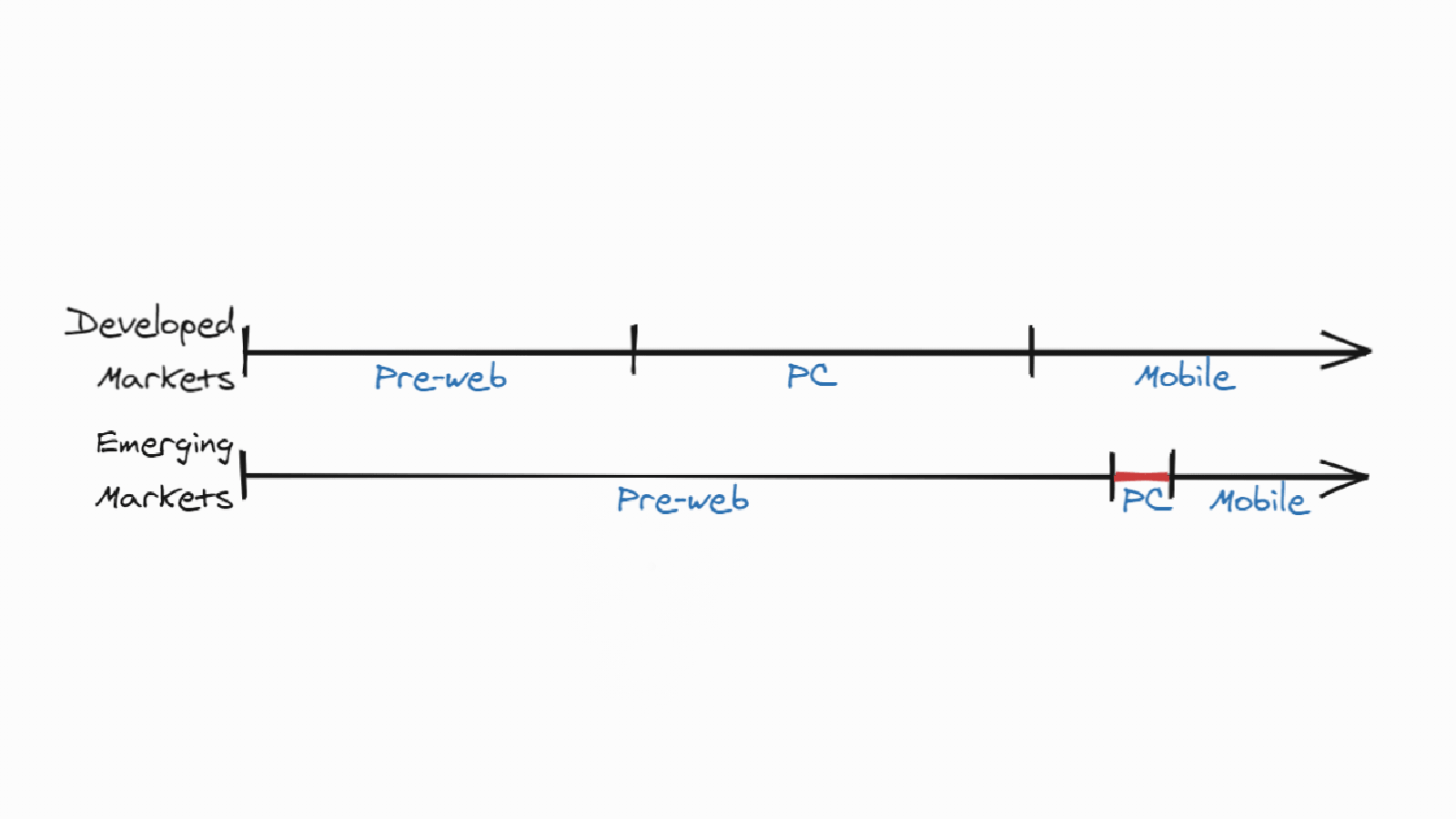
Super apps may enjoy a distinct advantage in markets with the following characteristics: cost-conscious consumers with low but growing purchasing power, high relative costs of internet data, relatively recent adoption of smartphones, and ‘mobile-first’ leapfrogging of the PC era.
Interesting analysis into how and why, after first appearing in Chinas and India with WeChat and Gojek, the Super App pattern - with one app as an ecosystem, instead of an ecosystem of apps like in “the West” - seems to repeat in other emerging markets across Asia and Africa.
What a gem! The reasoning and mechanics behind building an authentication system (Kerberos) in this case.
Athena: Well I’ve figured out how to secure an open network environment so that unscrupulous folks like you cannot use network services in other people’s names.
Best quote and Twitter thread on “artificial intelligence” so far:
Our field isn’t quite “artificial intelligence” – it’s “cognitive automation”: the encoding and operationalization of human-generated abstractions / behaviors / skills. The “intelligence” label is a category error
Sweet walkthrough of database models and their evolution: From flat-file, hierarchical, network, relational, noSQL, document, graph, column family to time series and back to NewSQL again: Prisma.io comparing database types.
Despite connections getting faster and faster and devices getting stronger and stronger, it appears the web is becoming slower and slower. As sites, apps, media and ads (especially ads) grow ever more ambitious, ever more featureful and sluggishly optimized, browsing turns to an exercise similar to commuting in the midst of rush hour stop-and-go, with every click bringing the browser to a gruding halt. Jake Archibald found a nice angle on the irony behind this, by measuring and analyzing page speeds of Formula 1 racing teams websites.
Amazingly detailled look behind the scences of a simple web request: How the web works. Great intro for total beginners and great refresher for those in the know.
Do you need this to: a) Scale, b) deploy, c) rapidly evolve or d) fail independently? Do you need to use e) non-standard technology? Or should this serve as f) façade? Then a microservice might be tge right pattern, else, maybe a monolith would serve you better. Should that be a microservice? great checklist and insights over @ Pivotal